This page was generated from historic/unit-5.1-mpi_ngsolve/mpi_basics.ipynb.
5.5.2 Basics of MPI-parallel NGSolve¶
[1]:
num_procs = '20'
[2]:
from usrmeeting_jupyterstuff import *
[ ]:
stop_cluster()
[3]:
start_cluster(num_procs)
connect_cluster()
Waiting for connection file: ~/.ipython/profile_ngsolve/security/ipcontroller-kogler-client.json
connecting ... try:6 succeeded!
Using MPI through NGSolve¶
For convenience, NGSolve provides access to a little bit of MPI-functionality through the python interface.
However, the general philosophy is that NGSolve should handle MPI-stuff on C++ side and not require the user to directly use it.
In cases where more MPI functionality is needed, mpi4py can be used.
Getting Started¶
MPI_Init returns a wrapper around the MPI-communcator used in NGSolve.
It provides some basic functionality, for example it can tell us the number of procs in it, and give us the rank of each one:
[4]:
%%px
from ngsolve import *
comm = MPI_Init()
print("Hello from rank ", comm.rank, ' of ', comm.size)
[stdout:0] Hello from rank 13 of 20
[stdout:1] Hello from rank 2 of 20
[stdout:2] Hello from rank 15 of 20
[stdout:3] Hello from rank 7 of 20
[stdout:4] Hello from rank 14 of 20
[stdout:5] Hello from rank 6 of 20
[stdout:6] Hello from rank 12 of 20
[stdout:7] Hello from rank 19 of 20
[stdout:8] Hello from rank 18 of 20
[stdout:9] Hello from rank 3 of 20
[stdout:10] Hello from rank 5 of 20
[stdout:11] Hello from rank 17 of 20
[stdout:12] Hello from rank 8 of 20
[stdout:13] Hello from rank 16 of 20
[stdout:14] Hello from rank 10 of 20
[stdout:15] Hello from rank 4 of 20
[stdout:16] Hello from rank 0 of 20
[stdout:17] Hello from rank 11 of 20
[stdout:18] Hello from rank 9 of 20
[stdout:19] Hello from rank 1 of 20
Additionally, "comm" provides:
time measurement
barriers
computing sums, minima, maxima
[5]:
%%px
t = comm.WTime()
s2 = comm.Sum(1)
t = comm.Max(comm.WTime()-t)
if comm.rank==0:
print('There are ', s2, ' of us, which took us ', round(t,6), 'seconds to figure out')
[stdout:16] There are 20 of us, which took us 0.017204 seconds to figure out
Distributed Meshes¶
When we load a mesh from a file in parallel, it gets distributed among the ranks and each one gets only a part of it, rank 0 gets nothing.
[6]:
%%px
mesh = Mesh('square.vol')
print('rank', str(comm.rank)+"'s part of the mesh has ", mesh.ne, 'elements, ', \
mesh.nface, 'faces, ', mesh.nedge, 'edges and ', mesh.nv, ' vertices')
[stdout:0] rank 13's part of the mesh has 4 elements, 4 faces, 9 edges and 6 vertices
[stdout:1] rank 2's part of the mesh has 2 elements, 2 faces, 6 edges and 5 vertices
[stdout:2] rank 15's part of the mesh has 3 elements, 3 faces, 8 edges and 6 vertices
[stdout:3] rank 7's part of the mesh has 2 elements, 2 faces, 7 edges and 6 vertices
[stdout:4] rank 14's part of the mesh has 3 elements, 3 faces, 7 edges and 5 vertices
[stdout:5] rank 6's part of the mesh has 3 elements, 3 faces, 7 edges and 5 vertices
[stdout:6] rank 12's part of the mesh has 4 elements, 4 faces, 9 edges and 6 vertices
[stdout:7] rank 19's part of the mesh has 3 elements, 3 faces, 10 edges and 7 vertices
[stdout:8] rank 18's part of the mesh has 2 elements, 2 faces, 8 edges and 7 vertices
[stdout:9] rank 3's part of the mesh has 3 elements, 3 faces, 8 edges and 6 vertices
[stdout:10] rank 5's part of the mesh has 3 elements, 3 faces, 10 edges and 7 vertices
[stdout:11] rank 17's part of the mesh has 3 elements, 3 faces, 9 edges and 9 vertices
[stdout:12] rank 8's part of the mesh has 3 elements, 3 faces, 7 edges and 5 vertices
[stdout:13] rank 16's part of the mesh has 4 elements, 4 faces, 9 edges and 6 vertices
[stdout:14] rank 10's part of the mesh has 2 elements, 2 faces, 5 edges and 4 vertices
[stdout:15] rank 4's part of the mesh has 3 elements, 3 faces, 8 edges and 7 vertices
[stdout:16] rank 0's part of the mesh has 0 elements, 0 faces, 0 edges and 0 vertices
[stdout:17] rank 11's part of the mesh has 2 elements, 2 faces, 6 edges and 5 vertices
[stdout:18] rank 9's part of the mesh has 3 elements, 3 faces, 7 edges and 5 vertices
[stdout:19] rank 1's part of the mesh has 4 elements, 4 faces, 10 edges and 7 vertices
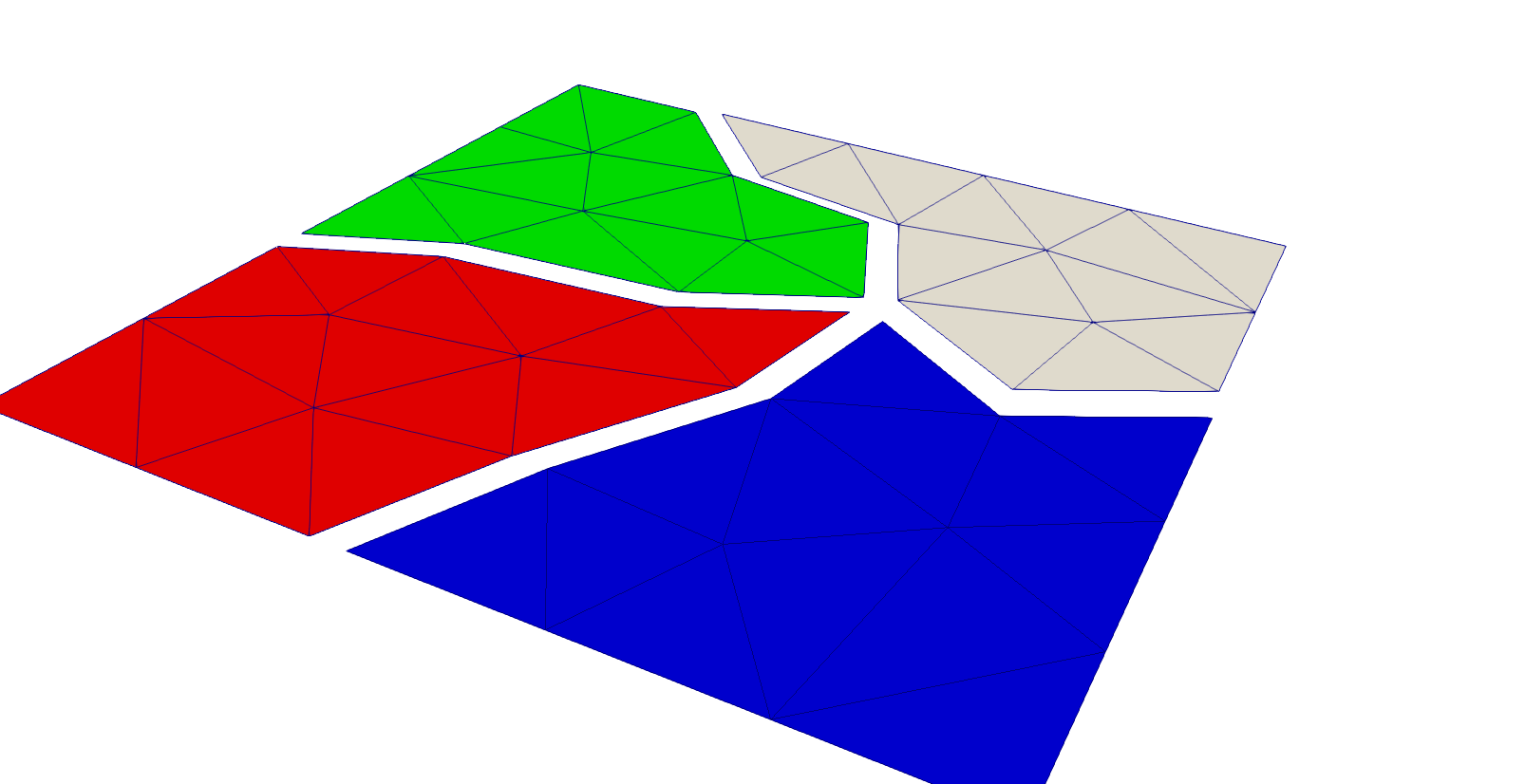
However, the entire geometry information is present everywhere:
[7]:
%%px --targets 0:5
print('rank', comm.rank, 'Materials:', mesh.GetMaterials())
print('rank', comm.rank, 'Boundaries: ', mesh.GetBoundaries())
[stdout:0]
rank 13 Materials: ('default',)
rank 13 Boundaries: ('bottom', 'right', 'top', 'left')
[stdout:1]
rank 2 Materials: ('default',)
rank 2 Boundaries: ('bottom', 'right', 'top', 'left')
[stdout:2]
rank 15 Materials: ('default',)
rank 15 Boundaries: ('bottom', 'right', 'top', 'left')
[stdout:3]
rank 7 Materials: ('default',)
rank 7 Boundaries: ('bottom', 'right', 'top', 'left')
[stdout:4]
rank 14 Materials: ('default',)
rank 14 Boundaries: ('bottom', 'right', 'top', 'left')
Distributed Finite Element Spaces¶
When we define a Finite Element Space on a distributed mesh, each rank constructs a Finite Element Space on it’s part of the mesh.
[8]:
%%px
fes = H1(mesh, order=3, dirichlet='bottom|left')
print('fes on rank', comm.rank, 'has', fes.ndof, 'DOFs, globally we have ', fes.ndofglobal)
[stdout:0] fes on rank 13 has 28 DOFs, globally we have 283
[stdout:1] fes on rank 2 has 19 DOFs, globally we have 283
[stdout:2] fes on rank 15 has 25 DOFs, globally we have 283
[stdout:3] fes on rank 7 has 22 DOFs, globally we have 283
[stdout:4] fes on rank 14 has 22 DOFs, globally we have 283
[stdout:5] fes on rank 6 has 22 DOFs, globally we have 283
[stdout:6] fes on rank 12 has 28 DOFs, globally we have 283
[stdout:7] fes on rank 19 has 30 DOFs, globally we have 283
[stdout:8] fes on rank 18 has 25 DOFs, globally we have 283
[stdout:9] fes on rank 3 has 25 DOFs, globally we have 283
[stdout:10] fes on rank 5 has 30 DOFs, globally we have 283
[stdout:11] fes on rank 17 has 30 DOFs, globally we have 283
[stdout:12] fes on rank 8 has 22 DOFs, globally we have 283
[stdout:13] fes on rank 16 has 28 DOFs, globally we have 283
[stdout:14] fes on rank 10 has 16 DOFs, globally we have 283
[stdout:15] fes on rank 4 has 26 DOFs, globally we have 283
[stdout:16] fes on rank 0 has 0 DOFs, globally we have 283
[stdout:17] fes on rank 11 has 19 DOFs, globally we have 283
[stdout:18] fes on rank 9 has 22 DOFs, globally we have 283
[stdout:19] fes on rank 1 has 31 DOFs, globally we have 283
[9]:
%%px
nd2 = comm.Sum(fes.ndof)
if comm.rank==0:
print('Strangely, the sum of all local DOFs is ', nd2, '!=', fes.ndofglobal)
[stdout:16] Strangely, the sum of all local DOFs is 470 != 283
If we just sum up the dimensions of the local spaces \(V^i\), we get the dimension of \(\Pi_i V^i\) and not the dimension of
Some base functions have to be shared across subdomains. Each subdomain takes the place of a macro Finite Element. 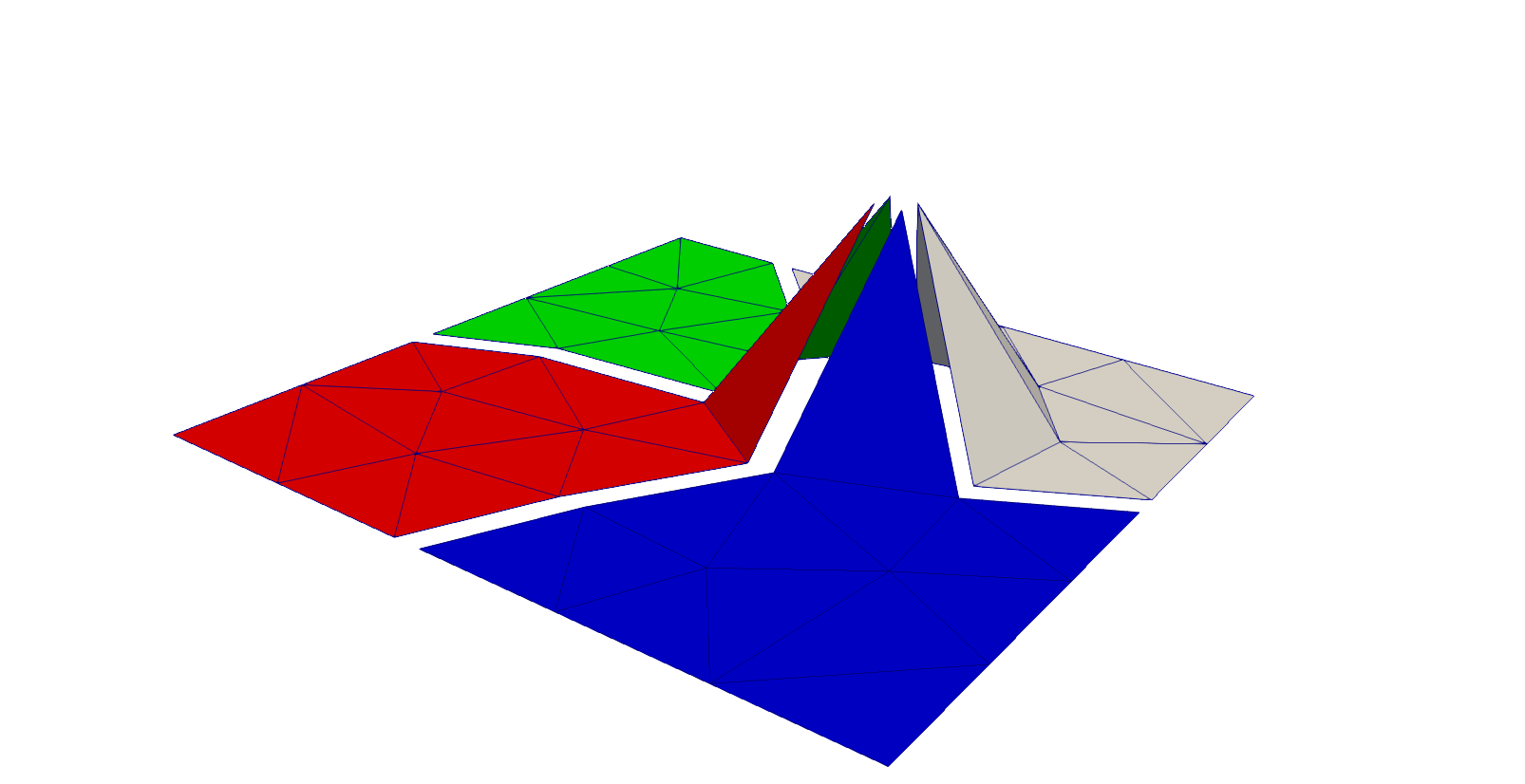
Information about how the DOFs stick together on a global level are stored in the "ParallelDofs" object:
[10]:
%%px
pd = fes.ParallelDofs()
print('rank', comm.rank, 'has', pd.ndoflocal, 'local DOFs, globally we have', pd.ndofglobal)
[stdout:0] rank 13 has 28 local DOFs, globally we have 283
[stdout:1] rank 2 has 19 local DOFs, globally we have 283
[stdout:2] rank 15 has 25 local DOFs, globally we have 283
[stdout:3] rank 7 has 22 local DOFs, globally we have 283
[stdout:4] rank 14 has 22 local DOFs, globally we have 283
[stdout:5] rank 6 has 22 local DOFs, globally we have 283
[stdout:6] rank 12 has 28 local DOFs, globally we have 283
[stdout:7] rank 19 has 30 local DOFs, globally we have 283
[stdout:8] rank 18 has 25 local DOFs, globally we have 283
[stdout:9] rank 3 has 25 local DOFs, globally we have 283
[stdout:10] rank 5 has 30 local DOFs, globally we have 283
[stdout:11] rank 17 has 30 local DOFs, globally we have 283
[stdout:12] rank 8 has 22 local DOFs, globally we have 283
[stdout:13] rank 16 has 28 local DOFs, globally we have 283
[stdout:14] rank 10 has 16 local DOFs, globally we have 283
[stdout:15] rank 4 has 26 local DOFs, globally we have 283
[stdout:16] rank 0 has 0 local DOFs, globally we have 283
[stdout:17] rank 11 has 19 local DOFs, globally we have 283
[stdout:18] rank 9 has 22 local DOFs, globally we have 283
[stdout:19] rank 1 has 31 local DOFs, globally we have 283
We can find out which DOFs are shared with which ranks.
[11]:
%%px --target=3
print('I am rank ', comm.rank)
print('---')
for k in range(min(10,fes.ndof)):
print('I share DOF', k, 'with ranks:', [p for p in pd.Dof2Proc(k)])
print('... and so forth ...')
print('\n')
for p in range(0, comm.size-1):
if len(pd.Proc2Dof(p)):
print('DOFs I share with rank', p, ': ', [p for p in pd.Proc2Dof(p)])
I am rank 7
---
I share DOF 0 with ranks: [8]
I share DOF 1 with ranks: [1, 2, 17]
I share DOF 2 with ranks: [1, 5]
I share DOF 3 with ranks: [5]
I share DOF 4 with ranks: [1, 5, 8]
I share DOF 5 with ranks: [5, 8]
I share DOF 6 with ranks: []
I share DOF 7 with ranks: []
I share DOF 8 with ranks: [8]
I share DOF 9 with ranks: [8]
... and so forth ...
DOFs I share with rank 1 : [1, 2, 4, 10, 11]
DOFs I share with rank 2 : [1]
DOFs I share with rank 5 : [2, 3, 4, 5, 12, 13, 14, 15, 16, 17, 18, 19]
DOFs I share with rank 8 : [0, 4, 5, 8, 9]
DOFs I share with rank 17 : [1]
There are a couple of points to consider here:
Locally, DOFs are numbered 0..ndoflocal-1.
There is no global enumeration!
The local numbering of DOFs is conistent across subdomain boundaries. (This just means that there exists some global enumeration of DOFs that is cinsistent with the local ones.)
Distributed Weak Formulations & Linear Algebra¶
Linear- or Bilinearforms can be split into subdomain contributions.
For example, the usual bilinear form \(a(\cdot, \cdot)\) associated to Poisson’s equation can be split into \(a_i(\cdot, \cdot)\) defined by:
When we write down BLFs and LFs for distributed FESpace, we actually simply write down it’s local contributions.
The FESpace figures out how to stick them together to form global forms.
[12]:
%%px
u,v = fes.TnT()
a = BilinearForm(fes)
a += SymbolicBFI(grad(u)*grad(v))
a.Assemble()
Let us see what we get after assembling the bilinear form:
[13]:
%%px --target=1
print('a.mat is a', type(a.mat))
a.mat is a <class 'ngsolve.la.ParallelMatrix'>
Parallel Matrices and Vectors¶
The general principle for distributed linear algebra objects is:
Parallel Object = Local Object + ParallelDofs
Matrices¶
[14]:
%%px --target=1,2
print('a.mat.local_mat on rank', comm.rank, 'is a', type(a.mat.local_mat), 'of dimensions', a.mat.local_mat.height, a.mat.local_mat.width)
print('lcoal fes ndof: ', fes.ndof)
print('a.mat.row_pardofs: ', a.mat.row_pardofs)
print('a.mat.col_pardofs: ', a.mat.col_pardofs)
print('fes pardofs: ', fes.ParallelDofs())
[stdout:1]
a.mat.local_mat on rank 2 is a <class 'ngsolve.la.SparseMatrixd'> of dimensions 19 19
lcoal fes ndof: 19
a.mat.row_pardofs: <ngsolve.la.ParallelDofs object at 0x2b5807f49c38>
a.mat.col_pardofs: <ngsolve.la.ParallelDofs object at 0x2b5807f49c38>
fes pardofs: <ngsolve.la.ParallelDofs object at 0x2b5807f49c38>
[stdout:2]
a.mat.local_mat on rank 15 is a <class 'ngsolve.la.SparseMatrixd'> of dimensions 25 25
lcoal fes ndof: 25
a.mat.row_pardofs: <ngsolve.la.ParallelDofs object at 0x2b824beacc00>
a.mat.col_pardofs: <ngsolve.la.ParallelDofs object at 0x2b824beacc00>
fes pardofs: <ngsolve.la.ParallelDofs object at 0x2b824beacc00>
Each rank assembles it’s local contribution to the global bilinear form into a sparse matrix, with dimensions matching that of the local FESpace!
Let us assume we have some global numbering, and assume that \(I_k\) is the set of indices corresponding to DOFs on rank \(k\).
The ebmedding matrices \(E_k\in\mathbb{R}^{n_i\times n}\) take local vectors of dimension \(n_k\) and gives us global vectors of dimension \(n\) .
The global matrix \(A\), operating on vectors of dimension \(n\), can be assembled from the local matrices in the same way we usually assemble our FEM matrices from element matrices:
Importantly, the local matrices are not simply diagonal blocks of the global matrix, \(A^i\) only has partial values for DOFs that are shared with another rank, \(A^{(i)} \neq E_i^T A E_i\).
Note¶
We never globally assemble \(A\)!!
A common approach used by other software packages is to actually assemble \(A\) and distribute it by rows.
Vectors¶
Things look very similar for parallel vectors, they are again implemented as short, local vectors that make up the global one:
[15]:
%%px
f = LinearForm(fes)
f += SymbolicLFI(x*y*v)
f.Assemble()
gfu = GridFunction(fes)
[16]:
%%px --target 1
print('length of vector: ', len(gfu.vec))
print('length of local vec: ', len(gfu.vec.local_vec))
print('dim local fes: ', fes.ndof)
print('dim global fes: ', fes.ndofglobal)
length of vector: 19
length of local vec: 19
dim local fes: 19
dim global fes: 283
Parallel Vectors additionally have a "ParallelStatus", which can be:
Cumulated, whenhe local vectors \(v^i\) are just restrictions of the global vector \(v\):
Distributed, when, similarly to parallel matrices, the global vector is the sum of local contributions
The vector of the linear form \(f\) is a collection of locally assembled vectors, so it is distributed.
The vector of the GridFunction gfu has been initialized with zeros, so it has consistent values, it is cumulated.
[17]:
%%px --target 1
print('status f vec: ', f.vec.GetParallelStatus())
print('status vec.local_vec: ', f.vec.local_vec.GetParallelStatus())
print('')
print('status gfu vec: ', gfu.vec.GetParallelStatus())
print('status vec.local_vec: ', gfu.vec.local_vec.GetParallelStatus())
status f vec: PARALLEL_STATUS.DISTRIBUTED
status vec.local_vec: PARALLEL_STATUS.NOT_PARALLEL
status gfu vec: PARALLEL_STATUS.CUMULATED
status vec.local_vec: PARALLEL_STATUS.NOT_PARALLEL
Multiplication of a parallel matrix with a cumulated vector gives a distributed one:
[18]:
%%px
v = gfu.vec.CreateVector()
w = gfu.vec.CreateVector()
v[:] = 1.0
w.data = a.mat * v
[19]:
%%px --target 1
print('status v: ', v.GetParallelStatus())
print('status w: ', w.GetParallelStatus())
status v: PARALLEL_STATUS.CUMULATED
status w: PARALLEL_STATUS.DISTRIBUTED
Solvers and Preconditioners with MPI¶
Not all solvers and preconditioners included in NGSolve also work with MPI, but many do: ### Direct Solvers
masterinverse: Collect the entire matrix on the "master" and invert sequentially there.
MUMPS inverse: Distributed parallel inverse, scalability is limited.
Preconditioners¶
BDDC
'hypre': Boomer AMG
'hypre_ams': Auxiliary Maxwell Space AMG
'local'
[20]:
%%px
c = Preconditioner(a, 'hypre')
#c = Preconditioner(a, 'bddc', inverse='mumps')
a.Assemble()
[21]:
%%px
gfu.vec.data = solvers.CG(mat=a.mat, pre=c.mat, rhs=f.vec, tol=1e-6, maxsteps=30, printrates=comm.rank==0)
[stdout:16]
it = 0 err = 0.1099777875557949
it = 1 err = 0.04115832958100785
it = 2 err = 0.01640413427737909
it = 3 err = 0.002399109415917421
it = 4 err = 0.002415741796640736
it = 5 err = 0.007649635824685178
it = 6 err = 0.005797037984086125
it = 7 err = 0.0018076379420930557
it = 8 err = 0.001549550034376465
it = 9 err = 0.003298447178932686
it = 10 err = 0.0016507909555561475
it = 11 err = 0.0006339283042538051
it = 12 err = 0.0002833425899718731
it = 13 err = 0.00010532173704651773
it = 14 err = 3.2319246923796026e-05
it = 15 err = 1.0179181507465682e-05
it = 16 err = 3.2057362836107735e-06
it = 17 err = 9.871239271369994e-07
it = 18 err = 2.7671426326565997e-07
[22]:
stop_cluster()